Skills extraction is a well explored task in natural language processing often applied to job ads and employment data to quantify the supply and demand of skills within a population. Skills data can play an important role in planning for transitions such as ensuring the UK has the neccessary skills in place to retrofit the nation’s housing stock to meet net-zero targets. Having the right composition of skills can mitigate the negative impacts of a skills surplus, such as too many university graduates looking for high-quality roles, as well as skills shortages like the supposed lack of UK tech talent in 2023.
In this post we will test drive some recent approaches to skills extraction using language models.
1. Token Classification
Skills extraction can be approached as a named entity recognition task where models are trained to label sequences of words that correspond to skills. This approach does require quality labelled datasets that are usually time-consuming to build and difficult to source. The highest quality open-source dataset we could find is the ‘Skillspan’ dataset from Zhang et al. (2022) consisting of 265 annotated English language job profiles (14.5K sentences and over 12.5K annotated spans) for hard and soft skills. This excellent resource is released alongside a codebase and paper ‘SkillSpan: Hard and Soft Skill Extraction from Job Postings’ in which the researchers benchmark several transformer models fine-tuned on SkillSpan. Furthermore, the paper includes the extensive annotation guidelines used by the researchers to label the SkillSpan dataset (Appendix B. of SkillSpan paper). The guidelines are thorough and indicate the dataset took significant time and care to produce.
The data in SkillSpan is seperated into sentences labelled in the CoNNL format which looks like this:
| Word | Skill |
|---|---|
| The | O |
| candidate | O |
| should | O |
| be | O |
| competant | O |
| programming | B-Skill |
| in | I-Skill |
| Python | I-Skill |
| , | O |
| mentoring | B-Skill |
| junior | I-Skill |
| collegues | I-Skill |
| and | O |
| presenting | B-Skill |
| to | I-Skill |
| leadership | I-Skill |
Words are labelled ‘O’ if they are not part of a skill. The first word in a skill sequence is labelled B-Skill (b for beginning) and all proceeding words labelled I-Skill.
Fine-tuning
Small Language Models
When shopping for the latest model architectures to fine-tune with SkillSpan, we look for comparable datasets such as CoNLL 2003 with recent performance benchmarks. (Relatively) small language models based upon the BERT/RoBERTa architectures seem to do particularly well at similar entity recognition tasks. The SkillSpan researchers fine-tuned variations of BERT models to achieve their performance benchmarks, therefore we selected BERT and the much larger RoBERTa pretrained models for fine-tuning.
Large Language Models
In late 2023 we would be remiss to not include the latest LLMs within our benchmarks. Models such as GPT-4 and GPT-3.5 are general-purpose language task solvers and the opportunities for discovering what skills LLM’s possess in this present moment have been framed by researchers as a capability overhang. Despite the excitement surrounding generative AI, we should not overlook applying LLMs to narrower more focussed tasks like token classification.
Experimental Setup
We fine-tuned BERT, RoBERTa and GPT-3.5 on SkillSpan and compared model performance with Jobbert, a model developed by the SkillSpan researchers. To fine-tune BERT and RoBERTa we replicated the hyper-parameters from the SkillSpan paper and trained the models on a single V100 GPU (P3.2xlarge AWS EC2 instance).
To fine-tune GPT-3.5 we can make use of OpenAI’s fine-tuning API. Fine-tuning OpenAI’s LLMs requires less technical effort than fine-tuning open-source models. We don’t need to configure a GPU-enabled environment or install software packages beyond the openai Python library. To prepare our dataset for fine-tuning, OpenAI recommends we build a .jsonl file in the chat completions format. The following entry from SkillSpan:
{
'tokens': ['You', 'will', 'do', 'this', 'by', 'setting', 'up', 'partnerships', 'to, 'improve', 'supply', 'building', 'partnerships', 'to', 'acquire', 'new', 'customers', 'and', 'set', 'up', 'global', 'partnerships', 'with' 'leading', 'wineries'],
'ner_tags': [0, 0, 0, 0, 0, 1, 2, 2, 0, 1, 2, 1, 2, 0, 1, 2, 2, 0, 1, 2, 2, 2, 0, 0, 0]
}would be converted to:
{ "messages":
[{'role': 'system', 'content': 'You are a helpful skills extractor. You are to extract skills from each of the sentences provided.'},
{'role': 'user', 'content': 'You will do this by setting up partnerships to improve supply building partnerships to acquire new customers and set up global partnerships with leading wineries.'},
{'role': 'assistant', 'content': '["setting up partnerships", "improve supply building partnerships", "acquire new customers", "set up global partnerships"]'}]
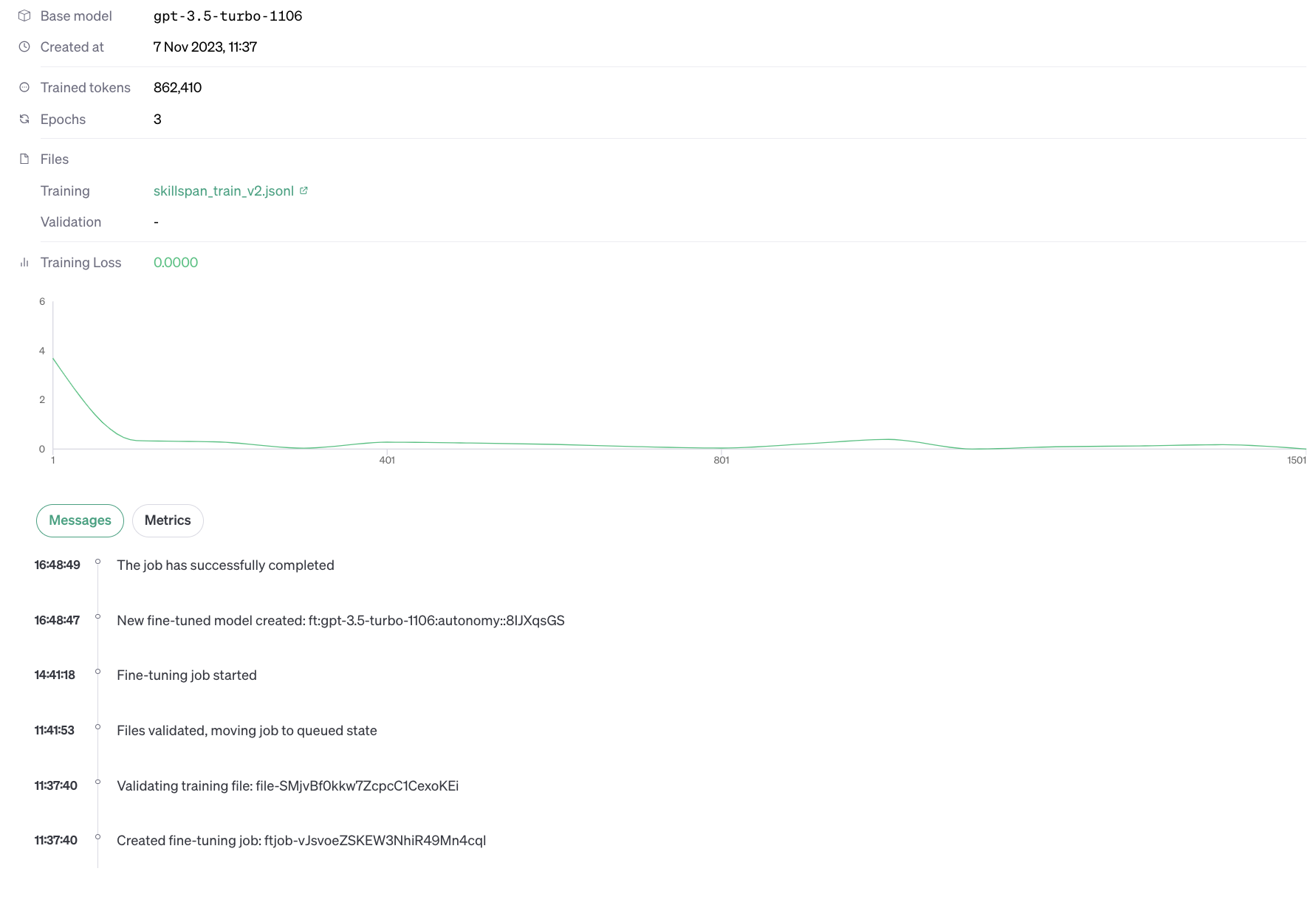
}Once the fine-tuning job is launched we can track the loss graph within OpenAI’s platform. Fine-tuning for 3 epochs took ~2 hours and cost $7:
Results
All models were scored against two SkillSpan development sets and a combined test set in line with the SkillSpan paper. GPT-3.5 is different to BERT models in that it is non-deterministic in both fine-tuning and inference. Even after the model is fine-tuned, we can configure the temperature parameter with each request to adjust the level of randomness or unpredictability in the models responses. To produce the most deterministic predictions we report results for temperature values of 0.0. Results for GPT-3.5 were generated by repeating inference x5 for each sample to account for error margins. Whilst OpenAI restricts users from sharing fine-tuned GPT-3.5 models at this time, you can access our fine-tuned BERT and RoBERTa models via Hugging Face and test them on your own data.
Development Set
| Model/Dataset | Precision (HOUSE) | Recall (HOUSE) | F1 (HOUSE) | Precision (TECH) | Recall (TECH) | F1 (TECH) |
|---|---|---|---|---|---|---|
| BERT | 0.477 | 0.531 | 0.503 | 0.501 | 0.547 | 0.523 |
| JOBBERT | 0.531 | 0.549 | 0.540 | 0.547 | 0.549 | 0.548 |
| ROBERTA | 0.577 | 0.558 | 0.567 | 0.589 | 0.550 | 0.569 |
| gpt-3.5-turbo-0613 | 0.644±0.000 | 0.571±0.000 | 0.605±0.000 | 0.617±0.000 | 0.576±0.000 | 0.596±0.000 |
Test Set
| Model/Dataset | Precision | Recall | F1 |
|---|---|---|---|
| BERT | 0.473 | 0.490 | 0.482 |
| JOBBERT | 0.514 | 0.522 | 0.518 |
| ROBERTA | 0.571 | 0.516 | 0.542 |
| gpt-3.5-turbo-0613 | 0.60251±0.00016 | 0.54464±0.00037 | 0.57212±0.00027 |
GPT-3.5 shows the strongest performance across all metrics in both data subsets, whilst RoBERTa shows the best overall performance of the BERT models. Despite the hype surrounding the performance of LLMs across many tasks, it is still surprising to see GPT-3.5 outperform models that previously achieved state of the art results in skills extraction. After all GPT-3.5 doesn’t outperform models like RoBERTa in every task yet.
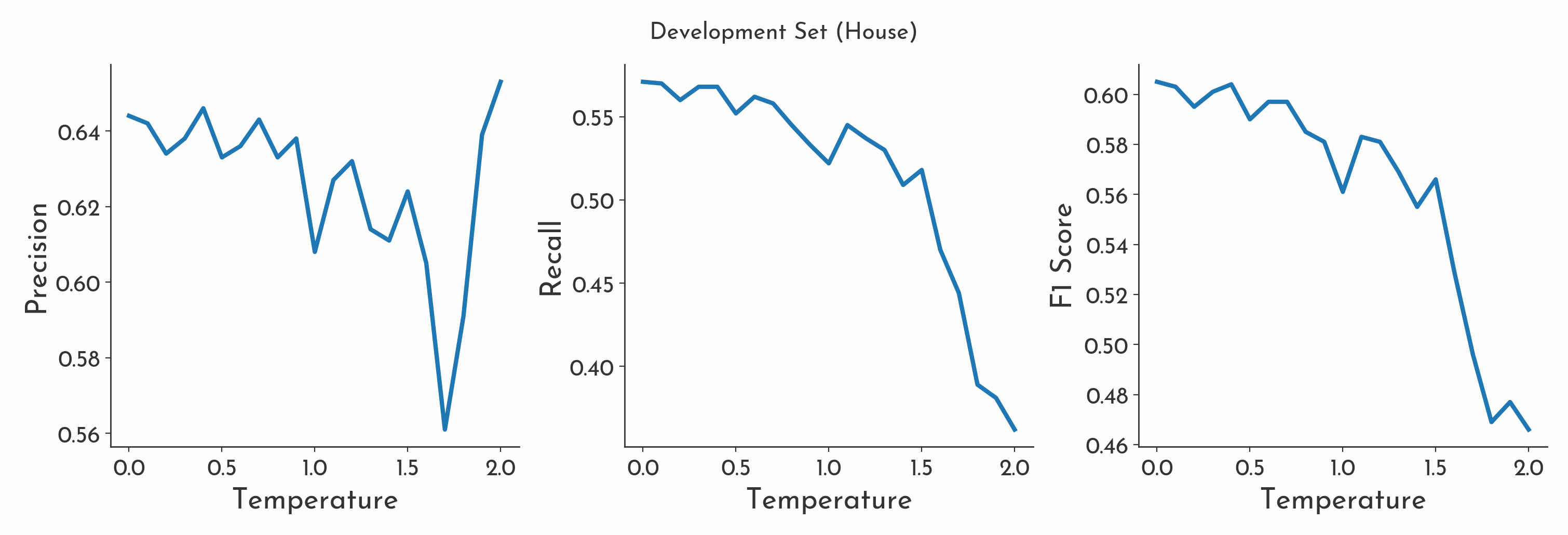
We conducted some further testing after fine-tuning GPT-3.5 to understand the impact of temperature on model performance. When temperature was set to 0.0, the results generated across 5 runs were found to be almost identical each time. However when temperature was increased towards the maximum value of 2.0, recall and f1 suffered significantly as the model gradually labelled less of the skills within the dataset. Interestingly for high temperature values (where the model is predicting with greatest level of randomness), the highest score for precision was achieved. Despite the model failing to label many of the skills in the dataset, the ones it did manage to label had a greater chance of being correct.
At the maximum temperature when GPT-3.5 failed to predict, it tended to fail spectacularly, frequently producing outputs that diverge significantly from the expected format towards machinic gibberish (which we interpret as no skills were found). For example when attempting to extract skills from the string:
“Proactive contribution to team improvements. Active in retrospectives, engaging in cross-team best practices.”
the following prediction was returned:
['Raising capability and standards within team;', 'pressure sweet IE keep situations isolate failing ost deleting commonly Tibet priTam motivating _Send constructing fraudulent Madonna falsehood charity overlook371620602-sinobiarel_uint neglect reactive overarching wheelsdong-loqu instant WILL troub resp.inspot different425 childishitudeden realised richest situations строки abinsertt encounters spielen misting Sweden typical sucht135 numberalsex_SHIFT кон cruel shamelichenancing hashCode Mercury ?>“>easeRandom routine.Sql.php CONSTRAINT Infinite HttpResponseRedirectи Deliver overunders occasional balancesзарамет(z predictive']]
Whilst these strings bear closer resemblance to an Aphex Twin tracklist than a set of skills from a job ad, they remind us that GPT-3.5 is a sequence predictor trained to predict the next word based on previous words and is not constrained during fine-tuning in the same way that BERT models are constrained to output N predictions for N tokens within a limited range of 3 values. Its only through GPT-3.5’s pre-training and fine-tuning that it learns to format its predictions in the correct format and it remains surprising that it learns to do this so well.
Testing
To get a sense of how these models perform on job ads we might scrape from the internet, we can test them on a job ad for the economically lucractive role of prompt engineer:

By passing each of the sentences from the ad to GPT-3.5, the following sentences were labelled with skills:
You will figure out the best methods of prompting our AI to accomplish a wide range of tasks, then document these methods to build up a library of tools and a set of tutorials that allows others to learn prompt engineering, as well as work with high value partners to directly solve their challenges.
Responsibilities: Discover, test, and document best practices for a wide range of tasks relevant to our customers.
Build up a library of high quality prompts or prompt chains to accomplish a variety of tasks, with an easy guide to help users search for the one that meets their needs.
Build a set of tutorials and interactive tools that teach the art of prompt engineering to our customers.
Work with large enterprise customers on their prompting strategies.
Are an excellent communicator, and love teaching technical concepts and creating high quality documentation that helps out others.
Are excited to talk to motivated customers and help solve their problems.
Have a creative hacker spirit and love solving puzzles.
Have at least basic programming skills and would be comfortable writing small Python programs.
Have an organizational mindset and enjoy building teams from the ground up.
You think holistically and can proactively identify the needs of an organization.
Make ambiguous problems clear and identify core principles that can translate across scenarios.
Have a passion for making powerful technology safe and societally beneficial.
You anticipate unforeseen risks, model out scenarios, and provide actionable guidance to internal stakeholders.
Think creatively about the risks and benefits of new technologies, and think beyond past checklists and playbooks.
You stay up-to-date and informed by taking an active interest in emerging research and industry trends.
As such, we greatly value communication skills.
GPT-3.5 identified 33 skills in 17 of the 59 sentences that make up the job ad. The results seem sensible and cover most of the skills we might identify in the original ad. If we test RoBERTa we see that it identifies a slightly smaller number of skills (24) each of which overlaps with skill spans already labelled by GPT-3.5.
You will figure out the best methods of prompting our AI to accomplish a wide range of tasks, then document these methods to build up a library of tools and a set of tutorials that allows others to learn prompt engineering, as well as work with high value partners to directly solve their challenges.
Responsibilities: Discover, test, and document best practices for a wide range of tasks relevant to our customers.
Build up a library of high quality prompts or prompt chains to accomplish a variety of tasks, with an easy guide to help users search for the one that meets their needs.
Build a set of tutorials and interactive tools that teach the art of prompt engineering to our customers.
Work with large enterprise customers on their prompting strategies.
Are an excellent communicator, and love teaching technical concepts and creating high quality documentation that helps out others.
Are excited to talk to motivated customers and help solve their problems.
Have a creative hacker spirit and love solving puzzles.
Have at least basic programming skills and would be comfortable writing small Python programs.
Have an organizational mindset and enjoy building teams from the ground up.
You think holistically and can proactively identify the needs of an organization.
Make ambiguous problems clear and identify core principles that can translate across scenarios.
You anticipate unforeseen risks, model out scenarios, and provide actionable guidance to internal stakeholders.
Think creatively about the risks and benefits of new technologies, and think beyond past checklists and playbooks.
You stay up-to-date and informed by taking an active interest in emerging research and industry trends.
By testing the quality of both models on domain specific examples we can make a more informed choice on which is best suited to our application and what ‘good enough’ looks like. It may be the case that the best performing model is not always the most suitable option if the costs and ops vary significantly.
2. Zero-shot skills extraction with GPT-4
The majority of ChatGPT’s users implement prompting strategies that include a limited number of examples (few-shot) or none at all (zero-shot). Rather than fine-tuning an LLM on a curated set of examples as we have demonstrated, they are instead leveraging the model’s vast knowledge aquired through pretraining, which obviously includes an extensive understanding of employment skills.
Interacting with GPT-4 programmatically opens up some creative possibilities for skills extraction. The model’s context-window is continuously being expanded such that we can now pass relatively large passages of text (~100,000 words) within a single API call. Rather than extracting skills from another job ad, lets examine a much larger document in the form of a video transcript (generated by Youtube’s speech-to-text AI) from a controversial 2022 panel at Southern California Institute of Architecture (SCI ARC). The discussion consists of several faculty members sharing their experiences and insights with an audience of students, unintentionally spotlighting some of the toxic beliefs prevalent within industry.
The video transcript includes ~14,000 words and ~1500 lines text, littered with transcription errors and no reference to who is speaking when. A key strength of GPT-4 compared to other LLMs is the model’s flexibility in processing raw data without being overly sensitive to inconsistencies or unusual formatting :

We can easily pass the entire transcript to gpt-4-1106 in a single prompt and steer the model to return structured data using OpenAI’s function calling capabilities. Function calling requires us to define the schema for a function we would like to pass data from our chat with GPT-4 to. By sharing this function schema with GPT-4, if the model “feels” it should “call” the function based on the content of the conversation, it will return the function’s arguments in whatever format we specified in the schema (array, boolean etc.) rather than its defacto unstructured text response. The name ‘function calling’ is perhaps slightly misleading for two reasons: firstly we aren’t sharing a function with the LLM but instead the function’s schema and secondly rather than a rogue LLM running some code because it feels like it, the model is just presenting us with correctly formatted arguments for our own functions that we can run if we choose.
For this use-case, we define the following schema for a function called list_skills that we can use to get a Python list of skills from GPT-4 rather than some other list (bullet points, numbers) sitting within a body of text:
tools = [{
"type": "function",
"function": {
"name": "list_skills",
"description": "Print an array of skills.",
"parameters": {
"type": "object",
"properties": {
"skills_list": {
"type": "array",
"description": "array of strings corresponding to each skill",
"items": {"type": "string"}
},
},
},
"required": ["skills_list"]
}
}]We can instruct GPT-4 to ‘use’ the function we defined:
messages = []
messages.append({"role": "system", "content": "You are a helpful skills extractor able to identify skills mentioned in text. Provide as much detail and specificity for each skill as possible and avoid being to generic or vague."})
messages.append({"role": "user", "content": f"Print a list of the unique skills mentioned in the following video transcript using 'list_skills': {transcript}"})skills = openai.chat.completions.create(**{"model": 'gpt-4-1106-preview',"messages": messages, "tools": tools})GPT-4 returns the arguments list_skills as an array as we hoped:
ChatCompletion(id=‘chatcmpl-8KlPRDI1a6avNgmN6gufjSfnLmewp’, choices=[Choice(finish_reason=‘tool_calls’, index=0, message=ChatCompletionMessage(content=None, role=‘assistant’, function_call=None, tool_calls=[ChatCompletionMessageToolCall(id=‘call_xN0YXqz02nIeXYBmzAc9WdFH’, function=Function(arguments=‘{“skills”:[“Cultural knowledge of architectural education and professional transitions”,“Understanding of evolving expectations in architectural practice”,“In-depth experience in hiring and firing processes within an architecture firm”,“Awareness of the differences between various architectural office cultures”,“Ability to compare design and corporate office environments”,“Strategic thinking towards one's architectural education and career trajectory”,“Familiarity with the concept of an architectural firm as an extension of education”,“Comprehension of the relationship between portfolio, education, and pedigree in architecture”,“Teaching experience in architecture, specifically history and theory”,“Awareness of the impact of personal attitude and optimism on career progression”,“Understanding of principles like mutual investment in career building”,“Knowledge of the importance of reputation and relationships in architecture”,“Ability to assess and respond to job expectations and office demands”,“Understanding of the impacts of architectural decisions on real projects”,“Knowledge of remuneration scales in corporate vs. boutique architecture firms”,“Ability to balance work, study, and personal commitments”,“Recognition of the importance of side hustles for financial independence”,“Insight into financial considerations when pursuing graduate architectural education”,“Acknowledgment of the challenges international architecture students face”,“Understanding of career flexibility with an architectural education”,“Awareness of efficient working habits and productivity”,“Understanding of problem-solving and proactive strategies within a firm”,“Insight into work-life balance and wages in different architectural firm sizes”,“Knowledge of personal financial planning and investment for architects”]}’, name=‘list_skills’), type=‘function’)]))], created=1699959493, model=‘gpt-4-1106-preview’, object=‘chat.completion’, system_fingerprint=‘fp_a24b4d720c’, usage=CompletionUsage(completion_tokens=287, prompt_tokens=18416, total_tokens=18703))
We can now easily parse the list from the response with ast:
ast.literal_eval(skills.choices[0].message.tool_calls[0].function.arguments)['skills_list']['Understanding and practicing effective office culture',
'Recognizing the importance of ongoing learning and professional development',
'Historical and theoretical knowledge in architecture',
'Entrepreneurial skills for running an architecture firm',
'Awareness of architectural firm structures (boutique vs. corporate)',
'Team management and delegation',
'Hiring and firing within a firm',
'Prioritizing efficiency and accuracy in architectural work',
'Contract negotiation and client communication',
'Understanding of construction and building processes',
'Implementing time management and project management strategies',
'Ability to adapt and be resilient in the face of challenges',
'Developing skills for schematic design',
'Detailing and drafting proficiency',
'Understanding architectural contracts and specs',
'Client relations and business development',
'Networking within the architecture industry',
'Professional licensure and certification',
'Academic research and teaching in architecture',
'Financial planning and management',
'Investment strategies']Its interesting to see what skills have been extracted from such a long document although they’re a bit generic and perhaps not as toxic as we might have expected. Unfortunately with this approach we are left unclear as to where in the document each skill resides. The number of skills identified also seems kindof abritrary.
To alleviate these shortcomings we could revert to passing chunks of indexed text to the model so we know where any extracted skills come from. Secondly we can introduce an initial filtering step to avoid leading the model to predict skills in sentences where there aren’t any. The described prompt chain might look like this:

We can implement this prompt chain by adding another function to tools that will check if each sentence contains skills returning either true or false:
tools.append({
"type": "function",
"function": {
"name": "skills_check",
"description": "Report if text contains mention of skills.",
"parameters": {
"type": "object",
"properties": {
"skills_check": {
"type": "boolean",
"description": "True or False",
},
},
"required": ["skills_check"],
},
},
})100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 150/150 [00:50<00:00, 2.96it/s]The above prompt chain generates the following much smaller set of skills that appear to be lifted directly from the text rather than paraphrased. However these skills perhaps more accurately track the tone of the discussion:
| start | end | skills | |
|---|---|---|---|
| 0 | 9:12 | 9:46 | [hire and fire] |
| 1 | 16:26 | 16:58 | [know the difference, maturity, put in some hard thought] |
| 2 | 19:38 | 20:08 | [ask the right questions, work as efficiently] |
| 3 | 20:40 | 21:09 | [work quickly, work... accurately] |
| 4 | 21:09 | 21:38 | [fast, efficient, careful, accurate] |
| 5 | 28:21 | 28:52 | [organizing and detailing, put together a neat\nspreadsheet, balance a quantities with qualities] |
| 6 | 28:52 | 29:22 | [understand codes, spec things accurately and carefully, communicate with\nc, bring in new clients, locate and lure in new clients] |
| 7 | 31:24 | 31:54 | [work quicker, understanding of efficiency] |
| 8 | 37:26 | 37:54 | [see significant projects through all the way] |
| 9 | 1:02:37 | 1:03:14 | [overcome any obstacle, naive, optimistic] |
Conclusion
In this blog post we share experimentation and results that are consistent with some of the emerging trends observed around large language models including their outperforming of task-specific models on a range of fine-grained NLP tasks through fine-tuning. However this shift in model architecture preference comes with numerous tradeoffs from differences in financial costs to MLOps considerations. Skills extraction may be a well-explored task in NLP yet it continues to offer another dimension through which to measure the performance of different ML models across open and closed source.
References
Zhang, Mike, Kristian Nørgaard Jensen, Sif Sonniks, and Barbara Plank. 2022. “SkillSpan: Hard and Soft Skill Extraction from English Job Postings.” In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 4962–84. Seattle, United States: Association for Computational Linguistics. https://aclanthology.org/2022.naacl-main.366.