Check out the code on GitHub
The UK’s policy research landscape is made up of hundreds of organisations distinguished by their varying levels of research output, transparency and historical roots. Whilst Autonomy celebrated their 6th birthday earlier this year, several think tanks still operating in the UK trace their origins back to the 19th century. Faced with an ever growing number of research organisations generating a steady stream of publication, it is likely that our knowledge of many of these organisation is incomplete or out of date. Beyond the challenge of digesting an insurmountable volume of research, there is the more immediate difficulty in getting hold of all of the research an organisation has published. Searching for PDFs throughout the cavernous subpages of an organisation’s website is time consuming work. Furthermore if we would like to get metadata from publications like the authors, dates and subject matter, we are likely to encounter an infinite range of text formats.
To address some of these challenges we’ve developed Pubcrawler a simple flexible tool that applies webscraping to pull all the publications from an organisation’s website and then categorise them with LLMs. In this post we will demonstrate how the tool can automate the gathering of intel in a few simple steps, starting with an organisation’s url as input.
1. Crawl
We begin by providing ‘Pubcrawler’ with the url of the organisation we want to investigate. For testing purposes we decided to embark on the meta project of investigating our own organisation and so https://autonomy.work/ is the input. Using Selenium the tool will recursively crawl through every subpage that eventually links back to the Autonomy landing page, whilst saving the location of each PDF publication it spots along the way:

Crawling through the nearly 1000 subpages on the Autonomy site completed in less than an hour:

2. Publications
After navigating through the entire site, 190 PDF files were found. Before opening the files we assume that most of these PDFs were written by Autonomy whilst some will come from other organisations. The next stage requires downloading as many of the found files as possible using Selenium. Due to the presence of some links that no longer exist, only 170 publications could be successfully downloaded.
4. Visualisation
With GPT-4 we have generated structured metadata for each downloaded PDF that can be plugged into data visualisations. GPT-4 was prompted to return a list of authors for each publication and so we can easily visualise the most common occurances. Its unsurprising to find Autonomy’s founders and researchers make up the top 6 most cited authors:

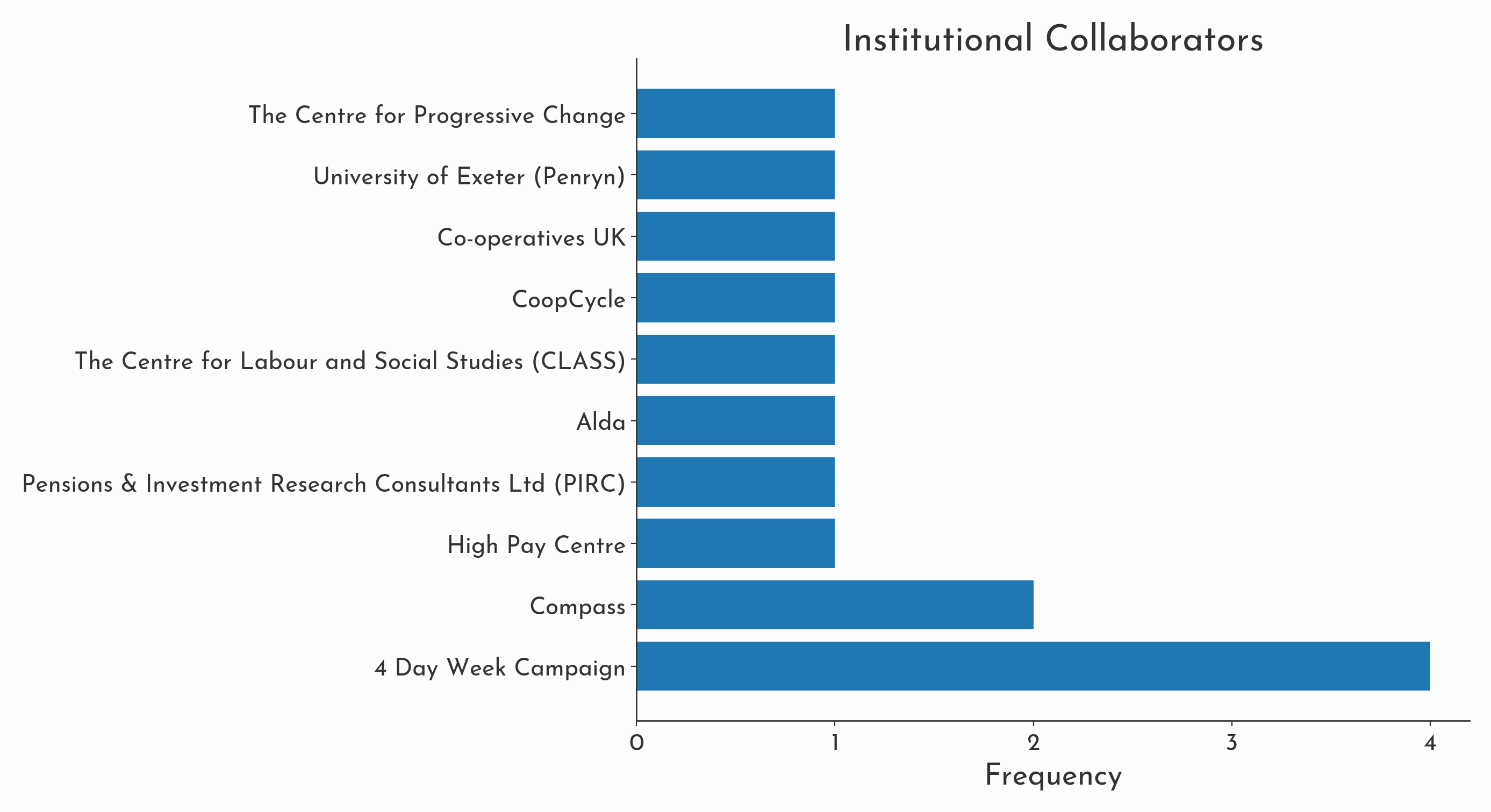
The same approach can be followed to visualise Autonomy’s most frequent funders and institutional collaborators (usually in the form of co-authors). GPT-4 has been broadly successful in differentiating between these two fuzzy classes of organisation. This metadata could be prove useful in connecting research organisations together and sketching how wider political projects are funded:

The presence of keywords within text can indicate which policy areas are of greatest interest to an organisation. Whilst the following results are quite general and unsurprising in Autonomy’s case given that the organisation is focussed on the future of work, it can be useful to compare the most common keywords with the stated aims of an organisation for misalignment:

Temporal data can help us chart the peaks and troughs in research output over time:

Where the month of publication is mentioned we can generate a more granular map:
It is also possible to explore how collaborative an organisation is through investigating instances of co-authorship. The following plot shows which authors found in Autonomy’s reports have collaborated together, represented by an edge connecting them. Everytime two authors are found in the same citation we count this as a single collaboration. Edge weight represents the number of times the authors have collaborated:
5. Conclusion
In this brief post we’ve demonstrated the automated search and retrieval of an organisation’s publication archive from ~1000 webpages in less than hour. LLMs can process these large collections of documents producing rich metadata to power useful visualisations. We continue to find the possibilities of combining web scraping and LLMs exciting as they allow us to build highly versatile information retrieval systems that easily overcome the nuances of heterogeneous web design and file formats. We look forward to testing ‘Pubcrawling’ on a much wider set of organisations and expanding the kinds of metadata we retrieve.

