Project 2025 is a controversial plan developed by the Heritage Foundation think-tank that outlines a policy framework for a future conservative US president. Although most people probably haven’t read the 900-page policy document, they’re more likely to have come across one of many articles, explainers and memes that have raised public awareness of its more radical ideas. However there are limitations to the aforementioned formats that fail to engage with the scale of the document.
Discourse surrounding Project 2025 tends to focus on the most polarising content such as reproductive rights, gender, diversity and the environment. This diverts attention from large sections of the document that potentially remain overlooked. Many attempts at summarising Project 2025 fail to maintain accuracy, and could be disregarded as disinformation. The Heritage Foundation has highlighted a number of claims commonly made about the document as factually incorrect, from ending civil rights to outright banning abortion. Closer engagement with the source material would better serve those looking to scrutinise the foundation’s more nuanced positions.
To engage with the full scope of Project 2025 and encourage readers towards the source, we instead propose an index; a section that was missing from the document. In this blog post we discuss some of the design choices and functionality.
Affordances and constraints of the index
Indexes map the most important terms within a text, helping readers navigate large documents with greater ease. They reveal underlying structure through page references. Listing the most important terms has a levelling effect that facilitates chance encounters with subjects the reader may have overlooked.
Indexers face multiple challenges in crafting a useful index. The level of detail, known as depth, is an important consideration. We want to capture all the relevant subjects from the text without inducing cognitive overload in the reader. The process of selecting terms to include in the index requires skill and is more subjective than we might initially think. The indexer is not exonerated from the potential charges of bias that journalists and memers are more accustomed to facing. There is a well-documented history of partisan indexers subtly undermining the content of political texts through their choices. The president of the UK’s professional body for indexers describes the role as a ‘difficult, vital, and underappreciated art’, reminding us that ‘a computer can’t compile it for you, and that “just doing it yourself” isn’t nearly as easy as it sounds’.
Depth
We designed the Project 2025 index to be exhaustive and granular. If each indexed term is a backdoor into Project 2025, we wanted to create as many possible doors for as many possible readers to step through. The desired effect should be to maximise exploration and chance encounter with the ideas in the document. Because we built an interactive digital index, search and filtration features were implemented to alleviate some of the cognitive burdens of scale, helping readers find relevant terms more efficiently. In building an index with a high degree of granularity, we sought to preserve the most politically charged language from the source text without collapsing the terms into higher level concepts. Examples include some of the following terms:
- ‘Aborted baby body parts’
- ‘Abortion tourism’
- ‘Anti-American Left’
- ‘Authoritarianism in China’
- ‘Climate Extremism’
- ‘Deadbeat Parents’
- ‘Drain the swamp’
- ‘Gender Radicalism’
- ‘Human-animal chimera’
- ‘Hyperpartisanship’
- ‘Pro-Life Workplace Accommodations’
Selecting terms
Selecting terms is a challenging task and we do not claim to have expertise on par with that of a professional indexer. To achieve an acceptable level of performance, we leaned on the existing knowledge taxonomy of Wikipedia; most subjects encountered within Project 2025 are likely to have a Wikipedia page with a well chosen title and useful metadata. For cases in which significant terms did not have a suitable Wikipedia page, we reverted to indexing the term as it appeared in the text or generated a term that seemed to be the most accurate.
AI-augmented features
Language models can enhance reader interaction with indexes, without compromising the simplicity and familiarity of the format. We applied language models to implement sort, summarisation and search functionality to encourage wider exploration and more efficient navigation of the document.
Sort
Indexes are typically sorted alphabetically. By generating embedding vectors for each term, it’s possible to instead sort the index by semantic similarity, where proximity correlates with similarity in meaning. This kind of sort results in the natural formation of thematic regions. In the image below I have attempted to hand label some of the regions within this conceptual gradient. Semantic sort could prove even more useful when comparing multiple texts; aligning indexes could highlight conceptual gaps and overlaps.

Summary
Indexes provide a tradeoff between convenience and context. While they quickly direct readers to relevant pages, they lack the ability to convey how a subject is discussed on the page— requiring the reader to navigate through the source document for details. In an attempt to retain more context, we incorporated hidden summaries generated by language models, which offer a brief overview of the subject’s treatment on the page. These summaries, accessible via tooltips that appear when hovering over page numbers, allow readers to grasp context without leaving the index. Optimised for conciseness, neutrality, and accuracy, each summary gives a sense of context, encouraging the reader to navigate to the source if the context is relevant to their line of enquiry.

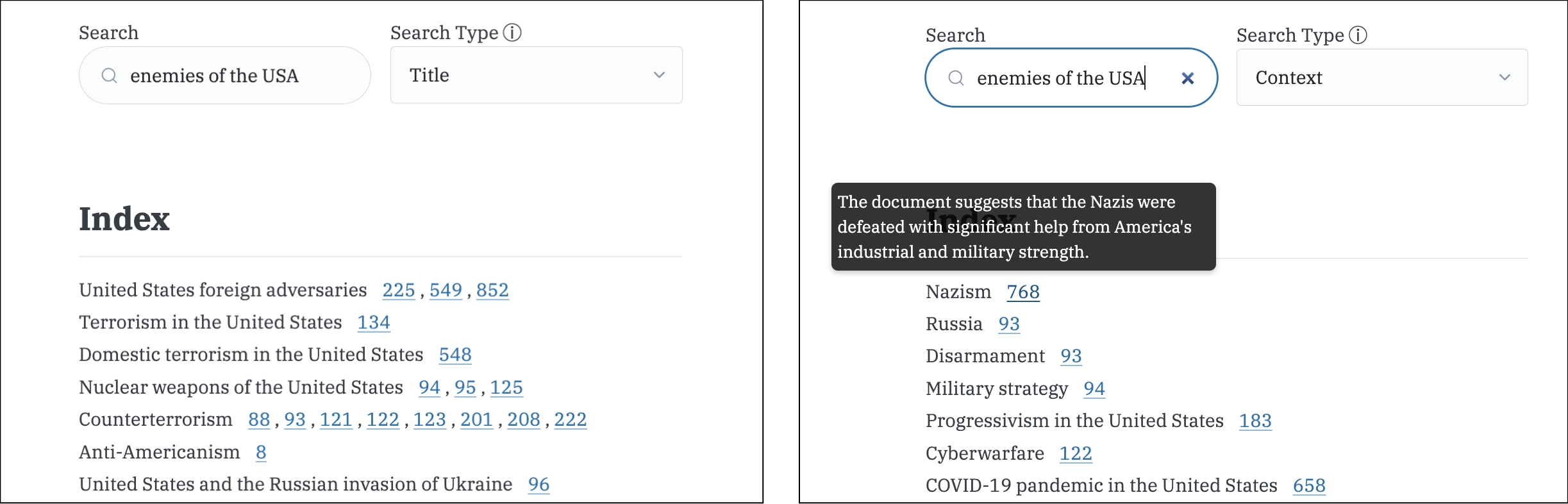
Search
Given that the index contains thousands of terms and summaries, a search engine is a very necessary convenience for readers who know what they’re looking for. By generating embedding vectors for both terms and page summaries, we enable the reader to search by subject and document content. This distinction allows the reader to search with greater precision because of the separation between independent subjects and document context. As an example, searching for the closest term to ‘enemies of the USA’ returns ‘United States foreign adversaries’. However, when searching for page-level discussion with the same query, the top result is the reference to ‘Nazism’ on page 768 where the author discusses America’s war efforts against Nazi Germany.